Chapter 2 Data Processing
2.1 FastQC
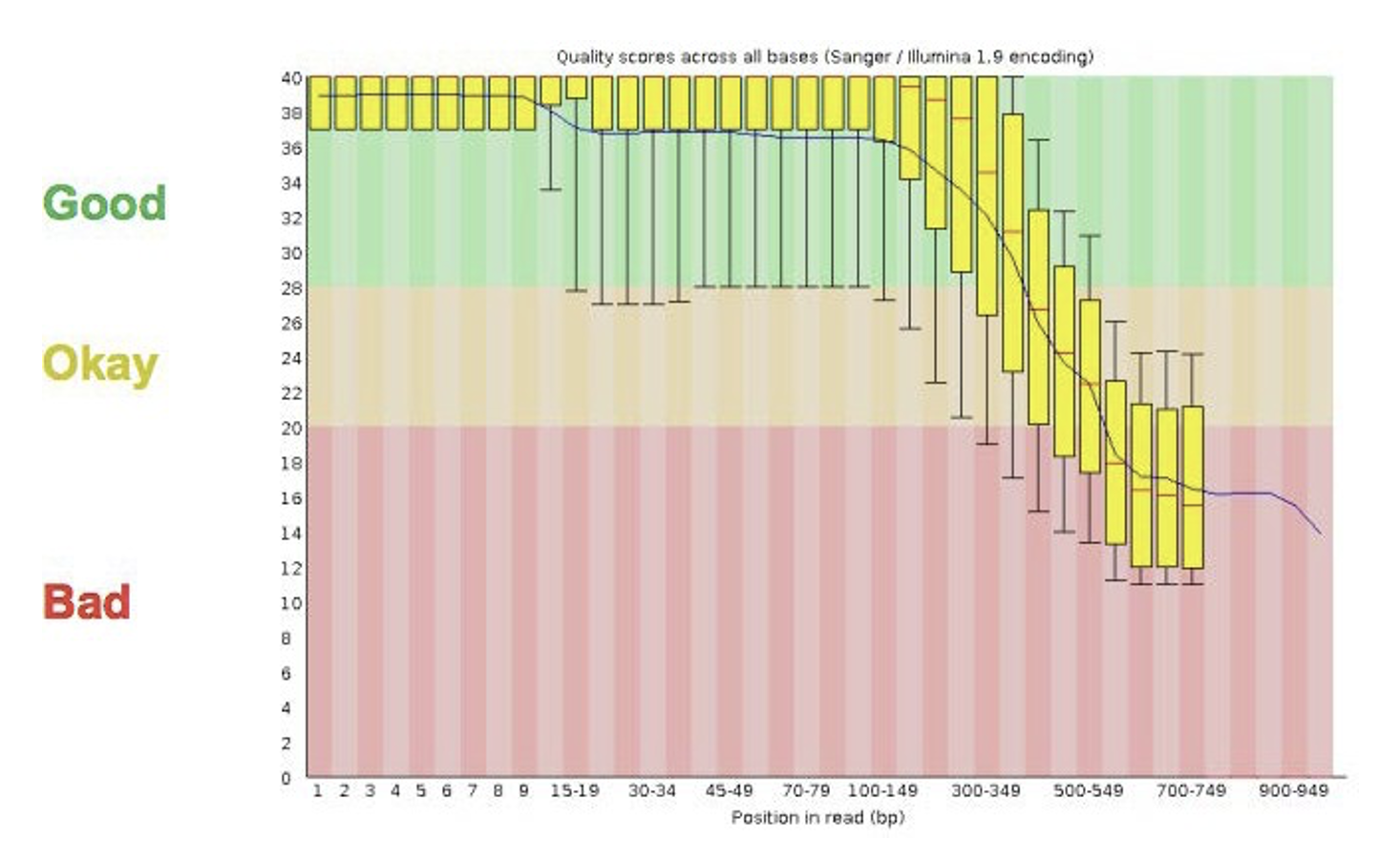
- Many tools/options to filter and trim data
- Trimming does not always improve things as valuable information can be lost!
- Removal of adapters is critical for downstream analysis
2.2 Dereplication
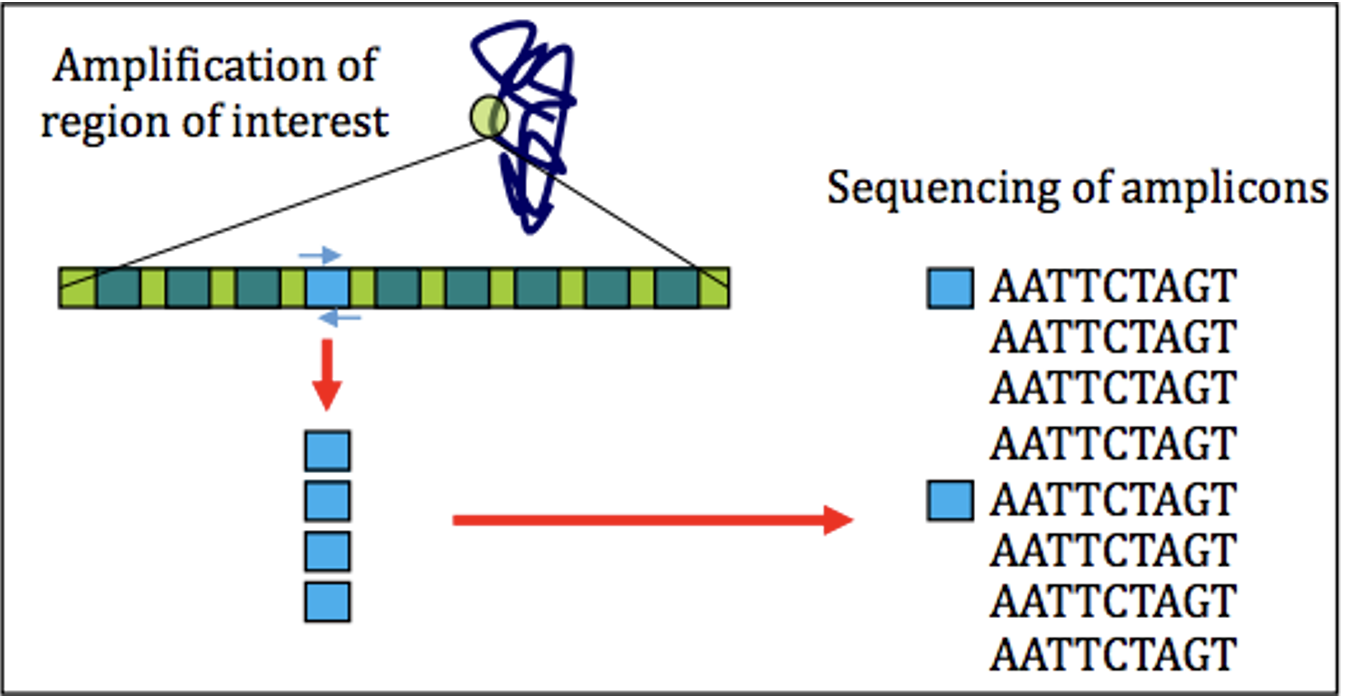
- In this process all the quality-filtered sequences are collapsed into a set of unique reads, which are then clustered into OTUs
- Dereplication step significantly reduces computation time by eliminating redundant sequences
What’s an OTU?
2.3 Chimera detection and removal of non-bacterial sequences
Chimeras as artifact sequences formed by two or more biological sequences incorrectly joined together
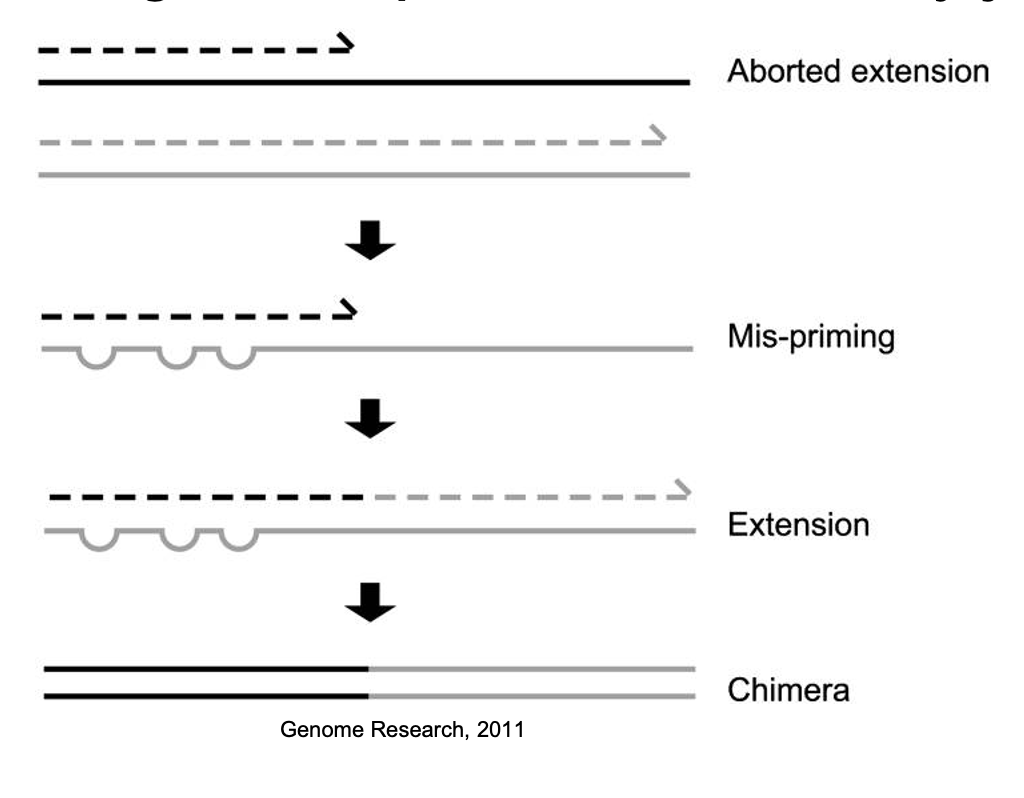
Incomplete extensions during PCR allow subsequent PCR cycles to use a partially extended strand to bind to the template of a different, but similar, sequence. This partially extended strand then acts as a primer to extend and form a chimeric sequence.
2.4 Clustering
- Analysis of 16S rRNA relies on clustering of related sequences at a particular level of identity and counting the representatives of each cluster

Some level of sequence divergence should be allowed – 95% (genus-level, partial 16S gene), 97% (species-level) or 99% typical similarity cutoffs used in practice and the resulting cluster of nearly identical tags (assumedly identical genomes) is referred to as an OTU (Operational Taxonomic Unit)
2.6 Bin OTUs into Taxonomy (assign taxonomy)
- Accuracy of assigning taxonomy depends on the reference database chosen
- Ribosomal Database Project
- GreenGenes
- SILVA
- Accuracy depends on the completeness of databases
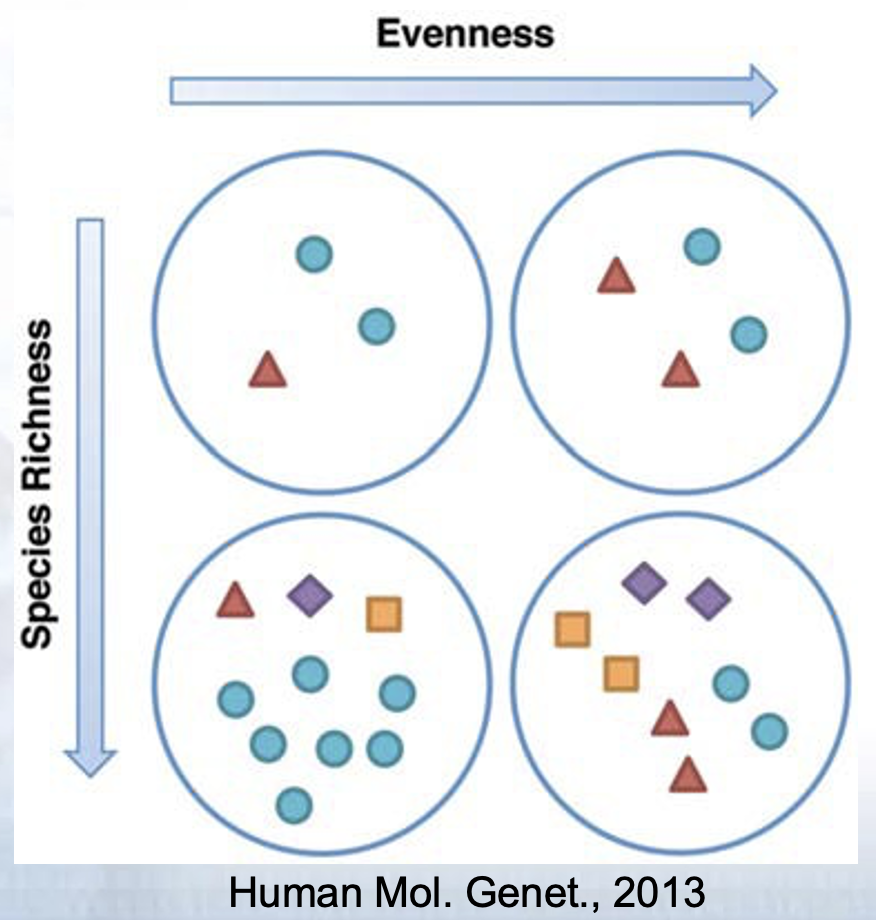
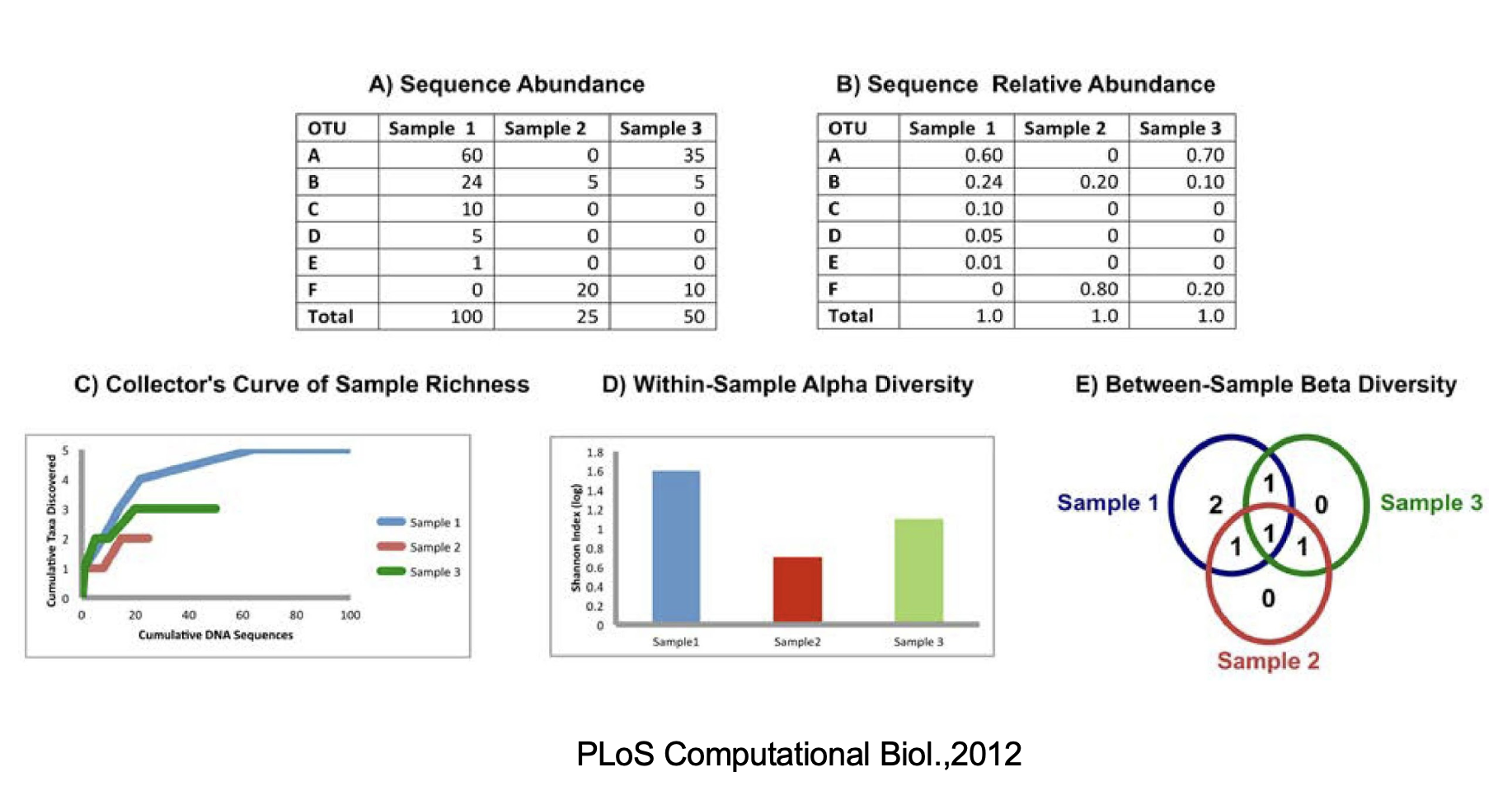
2.7 Assess Population Diversity: alpha diversity
- Assessment of diversity involves two aspects
- Species richness (# of species present in a sample)
- Species evenness (distribution of relative abundance of species)
Total community diversity of a single sample/environment is given by alpha-diversity and represented using rarefaction curves
Quantitative methods such as Shannon or Simpson indices measure evenness of the alpha- diversity
2.8 Assess Beta Diversity
- Beta-diversity measures community structure differences (taxon composition and relative abundance) between two or more samples
- For example, beta-diversity indices can compare similarities and differences in microbial communities in healthy and diseases states
- Many qualitative (presence/absence taxa) and quantitative(taxon abundance) measures of community distance are available using several tools
- LIBHUFF, TreeClimber, DPCoA, UniFrac (QIIME)
2.10 Diversity Measurements with 16s rRNA sequencing
- Overall Benefits
- Cost effective
- Data analysis can be performed by established pipelines
- Large body of archived data is available for reference
- Overall Limitations
- Sequences only a single region of the genome
- Classifications often lack accuracy at the species level
- Copy number per genome can vary. While they tend to be taxon specific, variation among strains is possible
- Relative abundance measurements are unreliable because of amplification biases
- Diversity of the gene tends to overinflate diversity estimates
- FastQC for 16S rRNA dataset
- Extremely biased per base sequence content
- Extremely narrow distribution of GC content
- Very high sequence duplication levels
- Abundance of overrepresented sequences
- In cases where the PCR target is shorter than the read length, the sequence will read through into adapters
2.12 Beta Diversity - UniFrac
- Measures how different two samples’ component sequences are
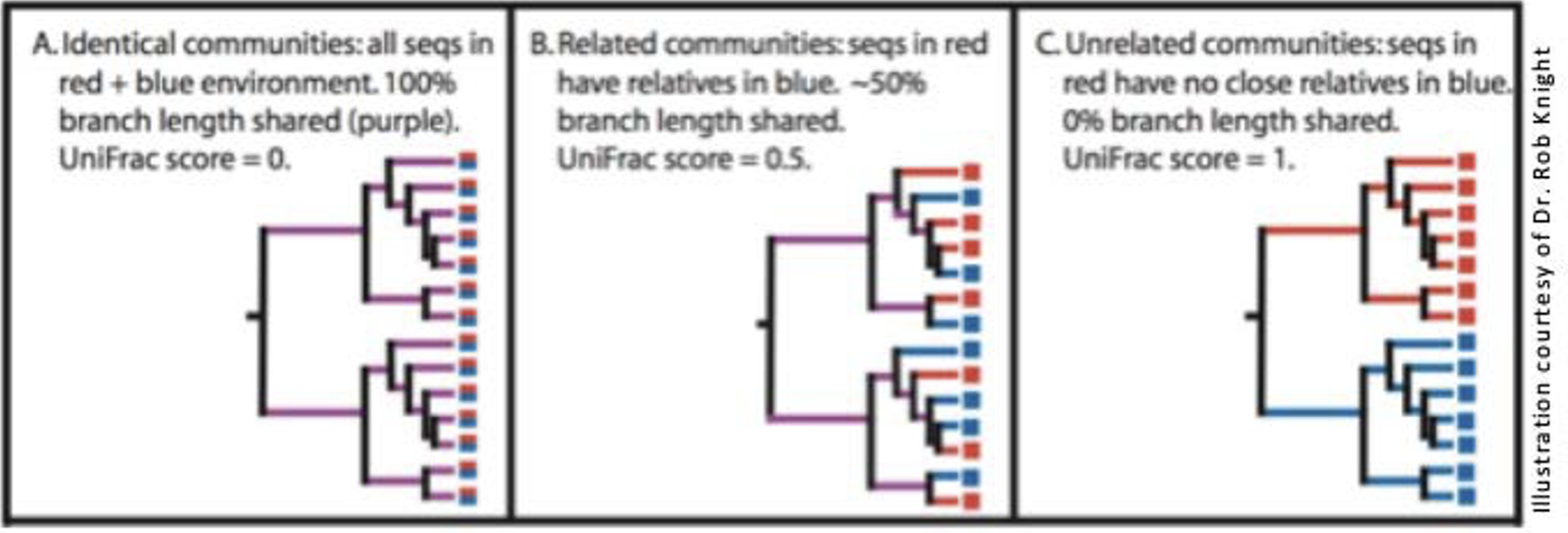
- Weighted Unifrac: takes abundance of each sequence into account
2.13 Results from Paper
- Main phyla: Firmicutes, Bacteroidetes, Proteobacteria, Actinobacteria, Fusobacteria with differences bw samples
- Sputum (patient) samples had highest diversity followed by oropharynx samples followed by nasal
- Healthy controls (N and O) more diverse than samples from TB patients
- Between-group comparisons?
- Phyla differences?